Building an agentic image generator that improves itself
Palash Shah
May 15, 2025
Background
At Bezel, we create personasA persona is detailed representation of a specific user-type or segment. We use personas at Bezel to help brands tailor their ads to specific consumers. Here, we asked the evaluator to reason whether a specific ad would appeal to a specific persona. An example persona could be: Dan, 31 years old, Software Engineer, Interested in playing basketball & spending time with family. for large brands, and help them run simulations on their content. Through this process, brands started asking us to generate ad inspirations tailored to their customers.
To begin, the OpenAI Image API was used to generate, and edit the images. It has two primary endpoints:
- The
/createendpoint is used to generate images. It takes a prompt, and returns a generated image. - The
/editendpoint is used to edit images. It takes an image, and a prompt, and returns an edited image. You are also able to provide masks to specify which parts of the image to edit.
In addition, we used a set of LLMs as evaluators to detect issues in the images using various methodologies:
o3was used to detect issues with text blurriness and image appeal. We tested various other reasoning models, and found that this was the most effective.gemini-2.5-flash-preview-04—17was used as a benchmark against o3 as a benchmark to compare performance.
Methodology
The goal was to build a system that automatically improves the quality of images generated by the OpenAI API. To do this, we needed a robust evaluatorAn evaluator is an AI system that assesses the quality or characteristics of generated content. In the context of LLMs, evaluators examine outputs against specific criteria, providing feedback that can be used to improve generation quality. This creates a closed loop system where one model critiques another model's work. to detect imperfections—such as distorted text or weak visual appeal—and an iterative feedback loop to refine the image with each pass.
Defining an Initial Prompt
We began by defining an initial prompt to generate our ad. As shown below, we settled upon a prompt that included various distinct, challenging components for an image generation model to create.
An ad for Redbull's summer campaign. It should include multiple flavors of RedBull, with lots of colors surrounding it. The image should be on a rooftop in SF, with lots of people socializing like a party. Include a discount code in plain text, on the bottom right.
We found that gpt-image-1 struggled to generate high-quality images from this prompt. While the overall concepts existed, the result felt like a blurry abstraction. The distinct visual elements seemed to overwhelm the model's ability to render each one in detail.
Approach 1: LLM-as-a-Judge for Text Improvement
Text Blurriness Detection
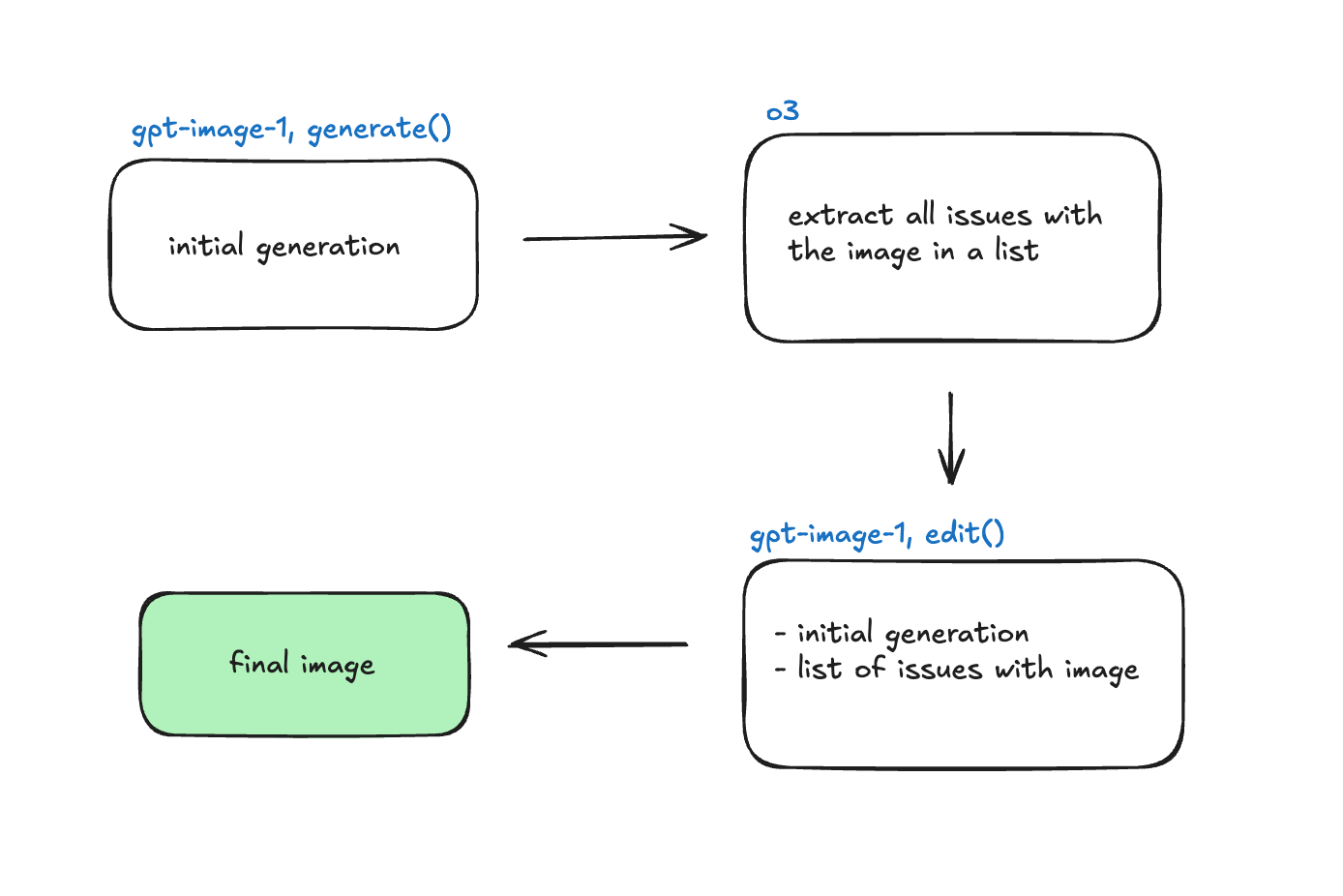
LLM-as-a-JudgeLLM-as-a-Judge is an evaluation approach where a large language model is prompted to assess the quality of generated content. In this context, we use it to identify issues in AI-generated images, particularly focusing on text clarity and visual coherence. was first picked as the evaluation method for blurry and distorted text. We started by prompting o3 to identify discrepancies in the initially generated image.
We took the output image from the prompt above, and requested o3 to identify all of the issues with the image related to text blurriness or distortion. The outputs looked like a sequence of specific issues like:
Orange can: supposed flavor name ('PEACH') is rendered in a thin, scratchy style that blends with the background; most letters are incomplete or missing, so the text is not legible.
LLM-as-a-judge implementation
Iteratively Editing the Image
After storing all of the generated issues, we prompted the /edit endpoint with the original image and this list of issues. Here's everything we learned about detecting & fixing these issues:
- You need to be really specific about what constitutes a flaw in the input image. We started to retrieve accurate flaws when asking specifically what it meant for text to be blurry.
- Reasoning models are far better as a multi-modal judge as opposed to more traditional models.
- Detecting abnormalities in an incremental loop (ask LLM to detect a singular issue, provide that issue + image, ask it to detect another until no remaining) works well. Very expensive, but has the highest accuracy. Below is a simplified pseudocode example of this implementation:
function detectAndFixIssues(image, prompt) {
let currentImage = image;
while (const issue = askLLM("Find ONE issue", currentImage)) {
currentImage = editImage(currentImage, issue);
}
return currentImage;
}With the LLM as a judge, we were able to pretty consistently generate improvements to an image's text blurriness across multiple iterations. The number of iterations usually hovered around 3, depending on the complexity of the image. We also found that there was a plateau in improvement after 3 iterations, indicating a technical ceiling to capabilities of the model.
Expanding Beyond Text: Composition and Appeal
Now that we had succesfully created an evaluator to detect issues in the text, we wanted to move to more abstract issues. The two issues that we were going to add the evaluator to detect were:
- Image composition: we asked
o3to reason whether the placing of all of the components of the image (background, product, text) was appealing. - Appeal: we asked
o3to reason whether, from the perspective of a specific persona, the image would appeal to them.
An example output from the evaluator is shown below:

Example of blurry text requiring improvement
1. **Text Clarity**: The product text on the cans is not entirely clear. The lettering appears distorted, making it difficult to read the brand and flavor information. Ensure the font is legible with sufficient contrast against the can's background. 2. **Blurriness**: The background featuring people and the skyline is slightly out of focus, which might be intentional to spotlight the cans. However, the focus on the cans should be sharper if they are the main product. Confirm the product is the focal point. 4. **Image Composition**: While most text is in frame, ensure the branding on each can is fully visible and not cut off. Consider repositioning the cans or adjusting the perspective. 5. **Overall Appeal**: The colorful powder effect adds visual appeal but ensure it does not overshadow or distract from the product itself.
The outputs now consisted of places where the image was distorted, observations on the image composition & positioning, and appeal to a group of personas.
Results & Limitations
The result was poor. Our hypothesis was as follows.
Our belief was that the model struggled because it was being asked to perform two fundamentally different tasks at the same time: one creative—improving image composition and alignment with target personas—and one technical—enhancing the pixel-level clarity of text elements.
To prove this hypotheses, we devised a secondary approach. In this approach, we would start with low quality generations, and an evaluator to fix issue with text clarity. Then, we would upscale, and create a separate LLM-as-a-judge to fix issues with image composition.
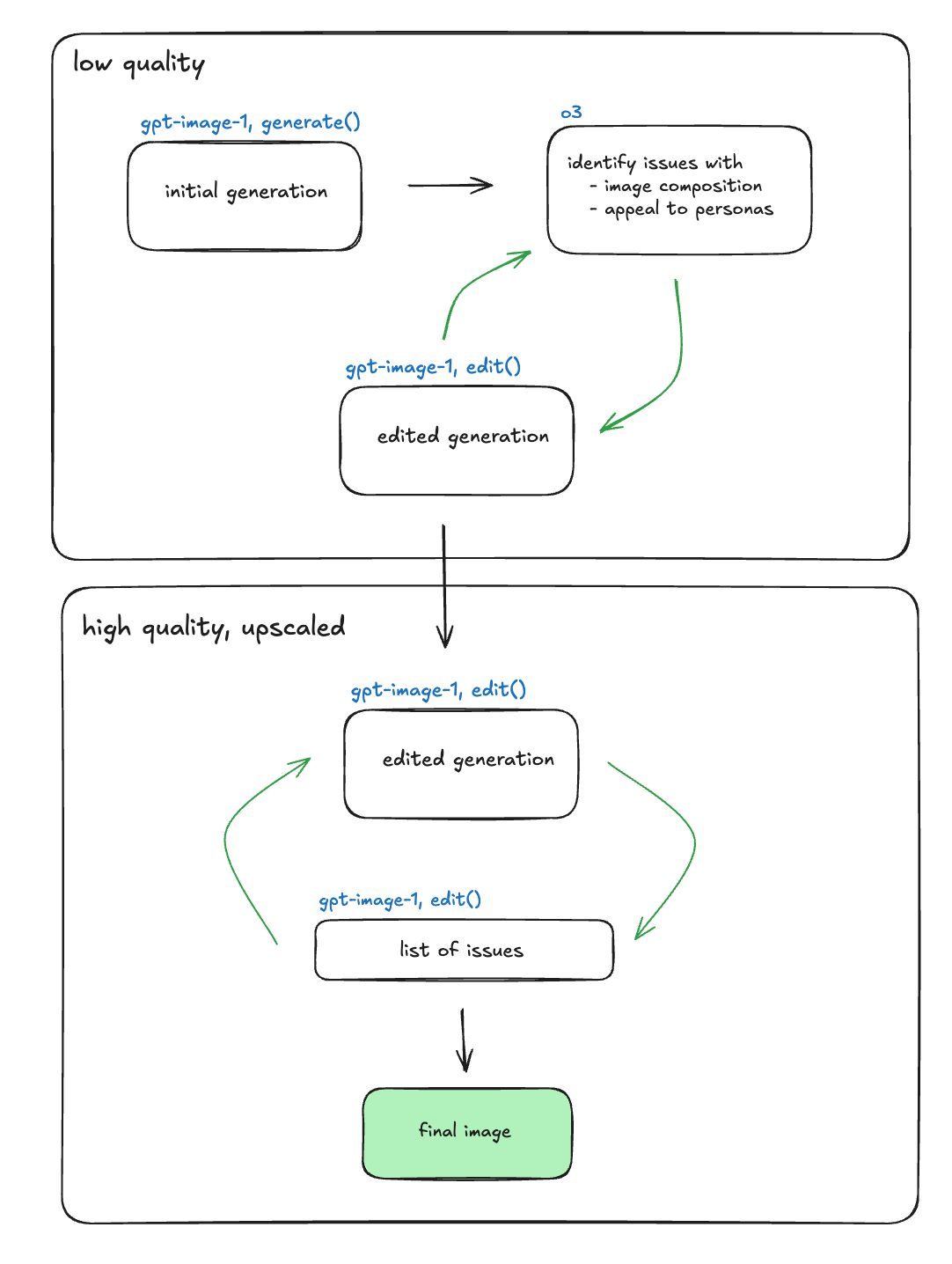
Top workflow is the text corrector, bottom is the quality module.

initial image

intermediary image

final upscaled image
This approach proved to be far more effective.
Approach 2: Bounding Box Method
One problem we found when using LLM-as-a-Judge for text blurriness was that the image modifications were not limited to just the issues enumerated by the evaluator. It often changed other parts of the image.
Text Blurriness Detection
For the purposes of identifying blurry text, we propose an alternative approach where we ask a reasoning model to generate the bounding boxes of the textual issues. Then, we provide those boxes as a mask of what to modify to the edit endpoint of the OpenAI API.
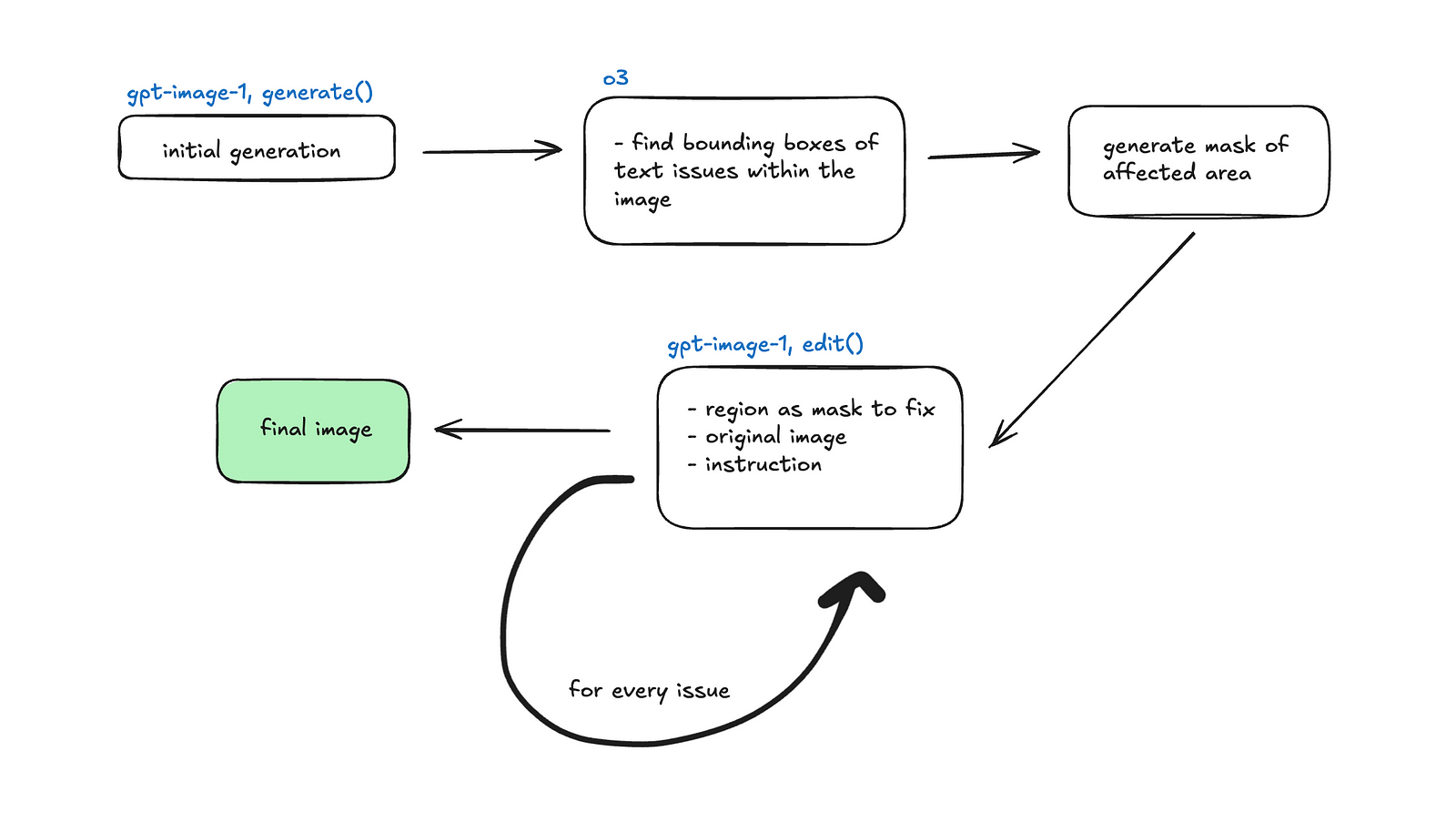
Bounding box approach
The prompt used for thisDescribe blurry text in this image and provide their bounding boxes in a JSON format. The text should be blurry and unreadable. These are pieces of text that need to be improved. The JSON should be an object with a 'description' field (string) and an 'objects' field (array). Each object in the 'objects' array should have a 'label' field (string) and a 'box' field (an array of 4 integers [x_min, y_min, x_max, y_max]). Assume the box coordinates are relative to the image dimensions (0-1 scale). Example JSON structure:[x_min, y_min, x_max, y_max]. We started by testing this with o3, with poor results. Just to verify that this was an issue generalizable to other LLMs we tested with gemini-2.5-flash-preview-04—17 as well.
Results & Limitations

gemini-2.5-flash bounding box detection

o3 bounding box detection
It became obvious that LLMs were unable to produce strong pixel associations. The LLM was able to consistently identify issues with the image that were accurate in natural language, but had a hard time converting that to points on the image plane. For example:
Brand name appears misspelled ('PodBul'), characters slightly blurry and distorted at box: [706, 634, 860, 808] (relative: [0.46, 0.62, 0.56, 0.79])
In the example above, the misspelling is correctly detected. However, the bounding box coordinates are not accurate, as they do not fully capture the problematic text.

Bounding box as a transparent mask
Due to the inaccuracy of the bounding boxes, providing them as a mask to the edit endpoint of the OpenAI API was not effective. We're omitting other methodologies of this approach for the purposes of this report.
Conclusion
Our exploration into agentic image generation revealed quite a bit about multimodal evaluators and editors.
While LLMs exhibit strong capabilities in natural language reasoning about visual imperfections,particularly semantic-level defects like illegible text or distorted branding, they struggle to map these high-level insights into precise pixel-space actions. This is especially evident in tasks requiring spatial accuracy, such as bounding box generation or localized masking.
We found that LLMs excel when reasoning is constrained to discrete, well-scoped dimensions, but their performance degrades when asked to balance abstract aesthetic judgments with deterministic pixel-level corrections. This mismatch suggests a disjunction in LLMs' ability to bridge symbolic understanding and spatial grounding—especially in iterative workflows that demand surgical image edits.
LLM-as-a-Judge should be the go-to methodology in multi-modal evaluations of image generations. We are at the precipice of a new era of image generation, where we can provide the road down which our models go, and watch them iteratively improve.